Generality
- Other than supervised learning, here we don’t know the labels for each data point.
- The task is to classify the data into clusters so that the clusters have similar properties
- A cluster is a collection of points close together in space:
- Each cluster has a center, the points near it are assigned labels of that center

Mathematics
General
- N data points \(X = [x_1, x_2,x_3,...,x_n]\in\mathbb{R}^{d.N}\)
- K < N is number of clusters.
- Find center \(M = [m_1,m_2,...m_k]\in\mathbb{R}^d\)
- Set \(y=[y_1,y_2,...,y_n]\) where \(y_i\) is the label of \(x_i\)
- If \(x_i\) is classified into cluster k, then \(y_i\) = k
- Sign: \(y_{i}^{(k)}\in\left\{0,1\right \},\sum_{k=1}^{k}y_{i}^{(k)}=1\) it mean each point belongs only to a single cluster.
Cost function
- \(m_k\) is the center of each cluster and estimates the points in this cluster.
- Each point \(x_i\) in cluster k has error is \((x_i - m_k)\).
- Error: \(\left\|x_i-m_k\right\|^2\) (Euclidean norm, “euclidean distance”)
Summary, Cost function for data set is: \(C(y, m)=\sum_{i=1}^{N}\sum_{j=1}^{K}y_{j}^{(i)}\left \|x_i-m_j\right\|^2\)
And we must find: \(y, m = \underset{y,m}{\arg\,min}\;\sum_{i=1}^{N}\sum_{j=1}^{K}y_{j}^{(i)}\left \|x_i-m_j\right\|^2\)
This is a two-variable function, so the easiest solution is to fix one variable and find the other as you learned in high school.
Fixed m, find y
Suppose found the centers, find labels so that C (meaning, m) is min.
Because each point only belongs to the closest cluster.
\[j=\underset{j}{\arg\;min}\left \|x_i-m_j\right\|^2\]Fixed y, find m
\[m_j=\underset{m_j}{\arg\;min}\sum_{i=1}^{N}y_i\left \|x_i-m_j\right\|^2\]Suppose found clusters for each point and find center to minimum cost.
Derivative:
\[\frac{\partial}{\partial m_j}\sum_{i=1}^{N}y_i\left \|x_i-m_j\right\|^2=2\sum_{i=1}^{N}y_i(m_j-x_i)\]Set equation = 0
\[2\sum_{i=1}^{N}y_i(m_j-x_i)=0\] \[\sum_{i=1}^{N}y_im_j-\sum_{j=1}^{N}y_ix_i=0\] \[\sum_{i=1}^{N}y_im_j=\sum_{j=1}^{N}y_ix_i\] \[m_j=\frac{\sum_{j=1}^{N}y_ix_i}{\sum_{i=1}^{N}y_i}\]- Denominator: data points in the cluster j
- Numerator: the total number of data points in the cluster j
So, \(m_j\) is mean of data points in cluster j, K-means clustering is born.
Algorithm
Input: Data X and k clusters. Output: Center M and label vector for each data points
- Step 1: Randomly select k points as the original centers.
- Step 2: Assign the data points to the cluster closest.
- Step 3: If the vector labels do not change from Step 2 => stop the algorithm.
- Step 4: Update the center for each cluster by taking the mean of all the data points assigned to the front of the cluster from Step 2
- Step 5: Go back Step 2.
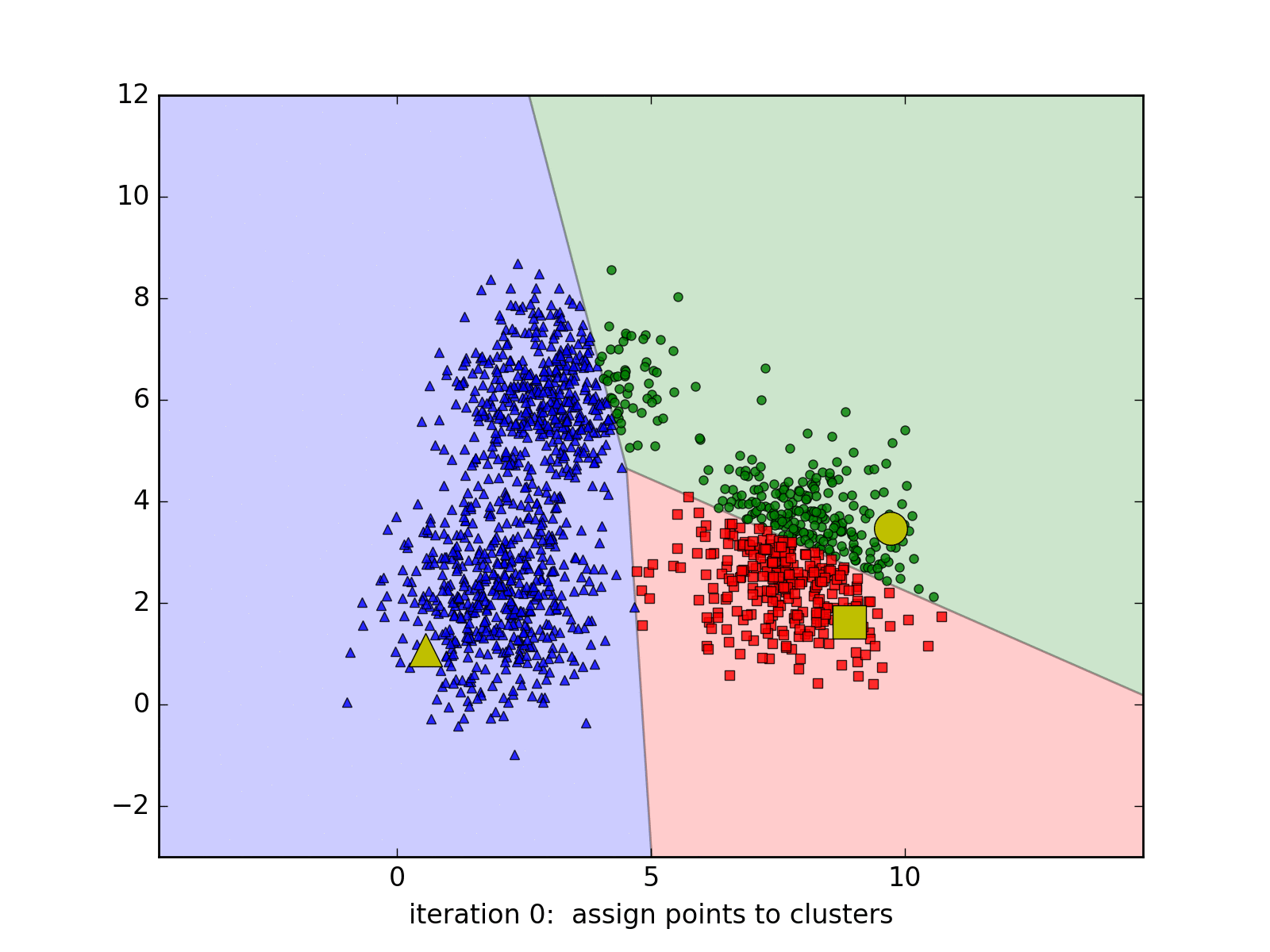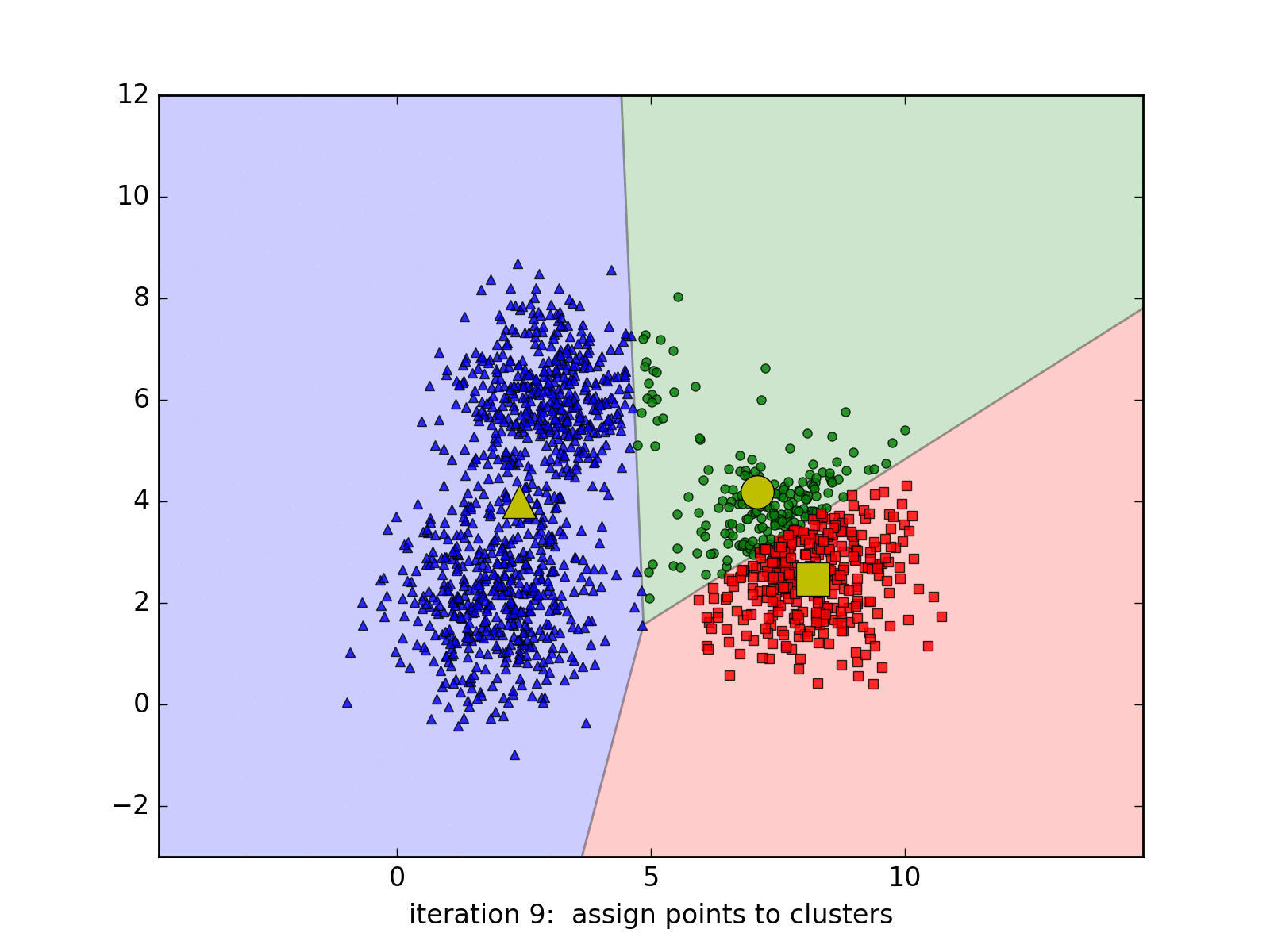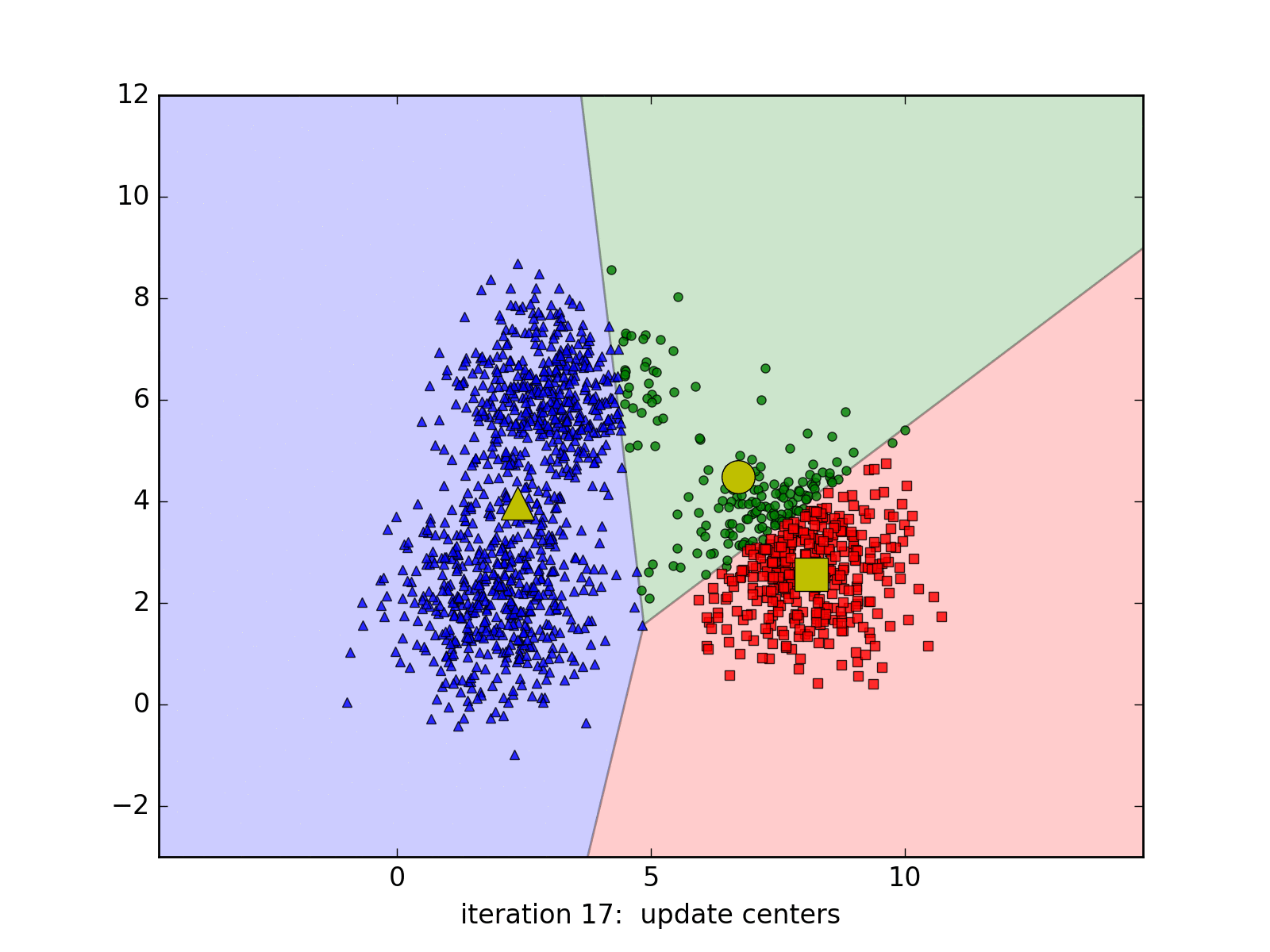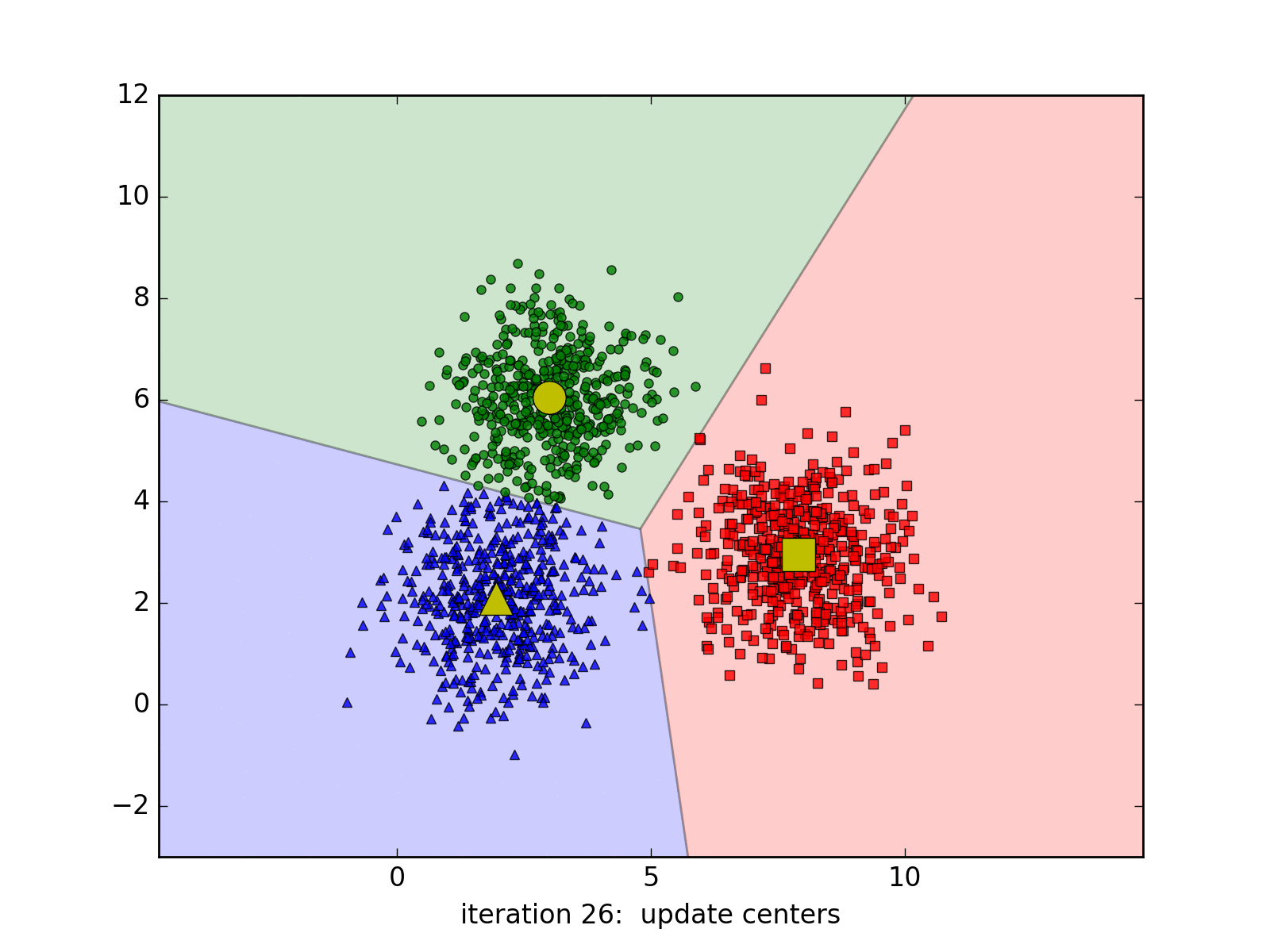
Source code by Python
Pick centers (Step 1)
def init_centers(X, k):
# Random pick k center from data
return X[np.random.choice(X.shape[0], k, replace=False)]
Assign data point
def assign_labels(X, centers):
# Compute Euclid norm by using
DE = cdist(X, centers, 'euclidean')
return np.argmin(DE, axis = 1)
Update centers
def update_centers(X, labels, k):
# Create new centers
centers = np.zeros((k, X.shape[1]))
for i in range(k):
# Take all elements in cluster i
Xi = X[labels == i, :]
# Update centers
centers[i, :] = np.mean(Xi, axis = 0)
return centers
Main K-means
def K_means(X, k):
centers = init_centers(X, k)
labels = []
while True:
# save pre_labels
labels_old = labels
# group data to a clusters
labels = assign_labels(X, centers)
# Check the change of centers
if (np.array_equal(labels_old, labels)):
break
# Updates centers
centers = update_centers(X, labels, k)
return (centers, labels)