Toán học trong Machine Learning
Một số kiến thức về đạo hàm, đạo hàm của vector hay một số dạng toán khác.
Norm (Chuẩn)
Trong không gian, chúng ta thường dùng khoảng cách Euclidean để đo khoảng cách giữa hai điểm.
Vậy nên có rất nhiều chuẩn norm và tính chất của chúng cũng có sự khác biệt.
Công thức tổng quát
Với p là một số không nhỏ hơn 1, biểu thức: \(\left\|x\right\|_p=(|x_1|^p+|x_2|^p+...+|x_n|^p)^{\frac{1}{p}}\)
được gọi là norm p.
Ta thường hay sử dụng:
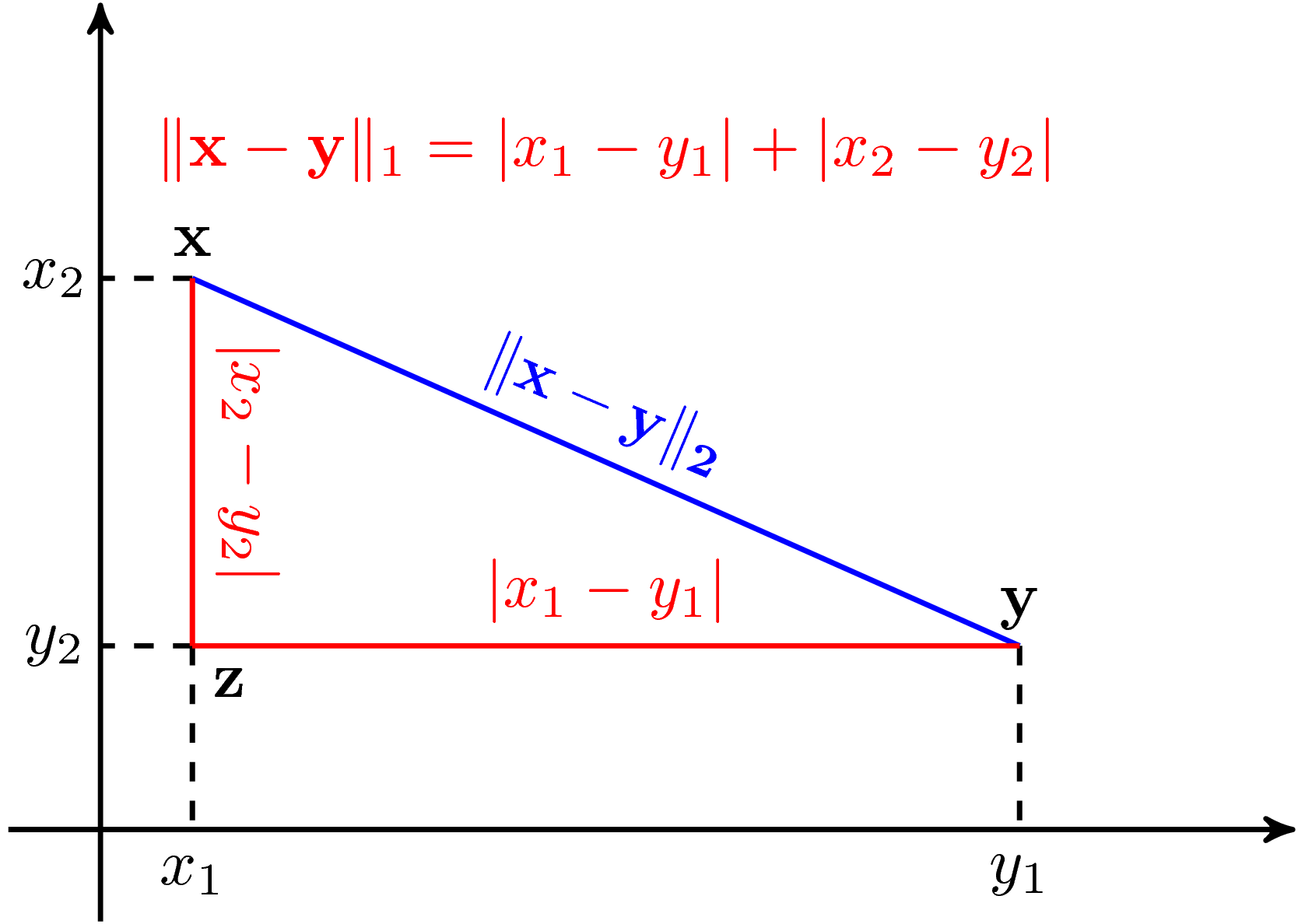
- \[p=1 \Rightarrow \left\|x\right\|_1=|x_1|+|x_2|+...+|x_n|\]
- \[p=2 \Rightarrow \left\|x\right\|_2=\sqrt{|x_1|^2+|x_2|^2+...+|x_n|^2}\]
Hình dưới đây là so sánh 2 norm này trong không gian hai chiều
Đạo hàm
Hai tính chất quan trọng
Product rule
Đây là luật lệ thường thấy trong đạo hàm của 2 biểu thức
\[\nabla{(f(X)^T g(X))}=(\nabla{(f(X))}.g(X) + (\nabla{(g(X))}.f(X)\]Đây là cách định nghĩa trừu tượng, thử đổi 1 cách giống như xưa nhé !
\[(f(x).g(x))'=f'(x).g(x)+f(x).g'(x)\]Chain rules
Đây là cách gọi của đạo hàm hàm hợp mà bạn đã từng học.
\[\nabla{_X g(f(X))}=\nabla{X}f^T\nabla{_fg(f)}\]Ngắn gọn và gần gũi hơn thì:
\[g'(f(x))=g'(f).f'(x)\]Hay đặt \(u=f(x) \Rightarrow u'=f'x\)
\[(g(u))'=g'(u).u'\]Bảng các đạo hàm thường gặp
Cho vector
| \(f(x)\) | \(\nabla{f(x)}\) |
|---|---|
| \(a^Tx\) | \(a\) |
| \(x^TAx\) | \((A+A^T)x\) |
| \(x^Tx=\left|x\right|_2^2\) | \(2x\) |
| \(\left |Ax-b\right |_2^2\) | \(2A^T(Ax-b)\) |
| \(a^Tx^Txb\) | \(2a^Tbx\) |
| \(a^Txx^Tb\) | \((ab^T+ba^T)x\) |
Cho ma trận
| \(f(X)\) | \(\nabla{f(X)}\) |
|---|---|
| \(a^TX^TXb\) | \(X(ab^T+ba^T)\) |
| \(a^TXX^Tb\) | \((ab^T+ba^T)X\) |
| \(a^TYX^Tb\) | \(ba^TY\) |
| \(a^TY^TXb\) | \(Yab^T\) |
| \(a^TXY^Tb\) | \(ab^TY\) |
| \(a^TX^TYb\) | \(Yba^T\) |
Đạo hàm riêng
Cụ thể, cho hàm số \(f(x, y)\) và một điểm \(M(x_0, y_0)\) thuộc tập xác định của hàm, khi đó đạo hàm theo biến \(x\) tại điểm M được gọi là đạo hàm riêng của \(f\) theo \(x\) tại M. Lúc này \(y\) sẽ được cố định bằng giá trị \(y_0\) và hàm của ta có thể coi là hàm 1 biến của biến \(x\).
Định nghĩa: \(f_x^{\prime}(x_0, y_0) = \lim\limits_{\triangle_x \rightarrow 0} \frac{\triangle_xf}{\triangle_x} = \lim\limits_{\triangle_x \rightarrow 0} \frac{f(x_0 + \triangle_x, y_0) - f(x_0, y_0)}{\triangle_x}\)
Với y tương tự như đạo hàm riêng của x
Công thức đạo hàm riêng của hàm hợp theo chain rule
\[F(u,v) = u(x,y)+v(x,y)\] \[\left\{\begin{matrix} \frac{\partial F}{\partial x} = \frac{\partial F}{\partial u}\frac{\partial u}{\partial x}\\ \frac{\partial F}{\partial y} = \frac{\partial F}{\partial v}\frac{\partial v}{\partial y} \end{matrix}\right.\]- Ma trận Jacobi của phép đổi biến \(u=u(x,y), v=v(x, y)\)
Đạo hàm theo hướng - Gradient
Bổ đề: \(\overrightarrow{l}\) là vector đơn vị.
Nếu ta kết hợp các đạo hàm riêng lại thành một véc-tơ và tính đạo hàm teo véc-tơ đó thì ta sẽ thu được đạo hàm toàn phần. Hay nói cách khác là đạo hàm theo tất cả các biến hay đạo hàm theo véc-tơ hợp thành đó. Đạo hàm này được gọi là gradient của hàm theo véc-tơ tương ứng.
Ta có gradient tại điểm M:
\[\nabla{f(x_0, y_0)} = \Bigg(\frac{\partial{f}}{\partial{x}}(x_0, y_0), \frac{\partial{f}}{\partial{y}}(x_0, y_0)\Bigg)\]Gradient là một vector cột, kí hiệu \(\nabla{f} = \Bigg[\frac{\partial{f}}{\partial{x}}\Bigg] \overrightarrow{i} + \Bigg[\frac{\partial{f}}{\partial{y}}\Bigg]\overrightarrow{i}\)
Ví dụ, hàm số \(f(x, y) = x^2 + y^2\) sẽ có gradient là: \(\nabla{f} = \begin{bmatrix} 2x \cr 2y \end{bmatrix}\)
Đối với hàm véc-tơ, nhớ lại rằng đạo hàm riêng của nó là một véc-tơ hàng mà gradient thành kết hợp theo véc-tơ cột, nên gradient của hàm véc-tơ sẽ là một ma trận có số hàng bằng với số chiều véc-tơ giá trị và số cột bằng với số biến.
\[J = \nabla f = \begin{bmatrix} \nabla f_1& \cdots &\nabla f_n \end{bmatrix}=\begin{pmatrix} \frac{\partial{f_1}}{\partial{x_1}} &\cdots & \frac{\partial{f_n}}{\partial{x_1}}\\ \vdots & \ddots & \vdots \\ \frac{\partial{f_n}}{\partial{x_1}} &\cdots &\frac{\partial{f_n}}{\partial{x_n}} \end{pmatrix}\]Ta có thể thấy rằng chiều của gradient sẽ cùng chiều với véc-tơ lấy đạo hàm. Hay nói một cách khác, hàm số tăng nhanh nhất khi theo hướng của gradient và giảm nhanh nhất khi ngược hướng với gradient của nó.
Tài liệu tham khảo
- Machine learning cơ bản
- Blog của dominhhai: Đạo hàm của hàm nhiều biến
- Matrix Calculus